
Text Encoding and Character Sets II
 Content of the lesson:
Content of the lesson:
- ASCII, 8-bit Encodings, Windows-1250, ISO 8859-2, CP852, Kód Kamenických, MacCE
- Unicode and Multibyte Sets
- Choosing Character Set
- Text Editors
- Conversion of Character Sets
- Online Tools
- Using Character Sets on Web
Introduction
If you work with a text in informatics technologies, all characters are processed as numerical values. Text encoding assigns characters to these numerical values using so called character sets. These sets can differ according to different languages.
Most of character sets assign an 8-bit number for characters (this is not a rule, you will see several exceptions later, for example 16-bit encoding).
ASCII
The oldest standardized character set is the ASCII code which was formed in 1963. The name ASCII is a shortcut from „American Standard Code for Information Interchange“.
The ASCII code is 7-bit which means that 7-bit number (number from interval 0-127) is assigned for every character. This code then contains 128 characters.
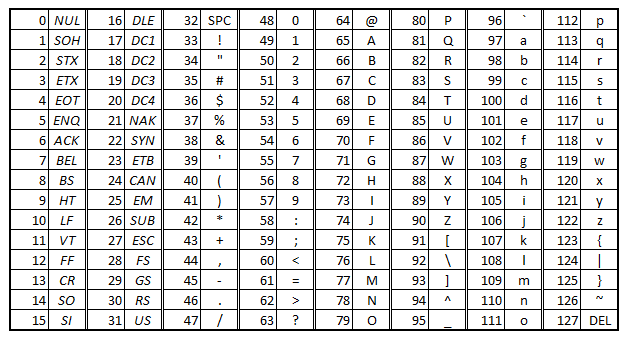
The main disadvantage of ASCII code is the fact that it only defines characters of English alphabet - 128 values cannot contain characters of all national alphabets which are used in different languages. Because of this the ASCII code was expanded to 8-bit code which uses 128 values of the previous ASCII code and additional 128 values for specific characters of each language (usually characters with diacritic). This part of ASCII code is not identical in all languages, it differs according to the used encoding.
8-bit Encodings
As mentioned in the previous chapter, ASCII code is a 7-bit character set which can store maximally 128 characters so it does not have enough capacity to store all characters of national alphabets. Because of this fact it was expanded to 8-bit character set which can store up to 256 different characters. The first 128 characters are usually identical with the original ASCII table and the next characters are inserted from national alphabets. These characters usually differ in different character sets.
8-bit character sets are sometimes marked with a common name ANSI (for example under operating systems MS Windows).
The Most Used Encodings for Czech Language (8-bit encodings)
There are several alternatives for 8-bit encoding of Czech language, especially these character sets:
- Windows-1250
- ISO 8859-2
- CP852
- Kód Kamenických
- MacCE
Windows-1250
Windows-1250 is a default character set for Czech language under MS Windows. This encoding can be used not only for Czech language but also for languages of central Europe (Albanian, Croatian, Polish, Slovak and more) and for German because the characters typical for German are at the same positions as in Windows-1252 encoding (used for western Europe).
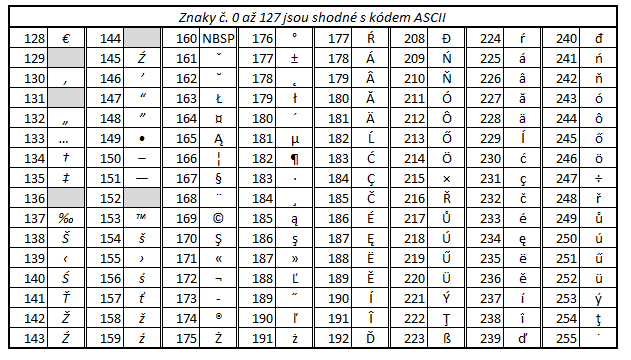
Note: Characters with grey background are not used. NBSP - non-breakable
space.
ISO 8859-2
ISO 8859-2 is another possible encoding of Czech characters. This encoding is defined as an ISO standard and its full name is ISO/IEC 8859-2. Sometimes you might also meet the name Latin-2 for this character set. This name is sometimes also used for the encoding CP852 from MS-DOS operating system so it is better to use names ISO Latin-2 for ISO 8859-2 and PC Latin-2 (or IBM Latin-2) for the older CP852 to differentiate them.
The character set ISO 8859-2 is often used under Unix operating systems, for example GNU/Linux.
If you compare the character sets Windows-1250 and ISO 8859-2 you will find out that they are very similar. These sets differ only in layout of several characters.
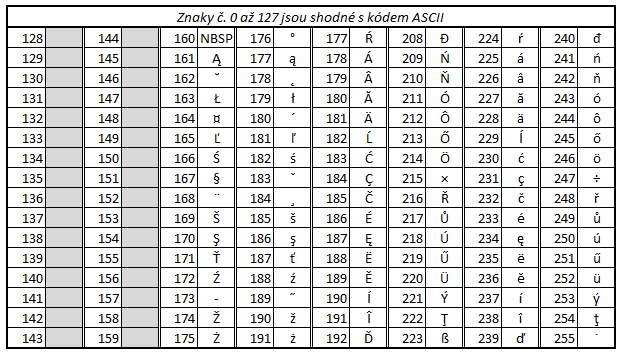
Note: Characters with grey background are not used. NBSP - non-breakable
space.
CP852
The character set CP852 (as already mentioned in the chapter about set ISO 8859-2 is sometimes being named as PC Latin-2 or IBM Latin-2) is a set for languages from central Europe and is usually used under the MS DOS operating system.
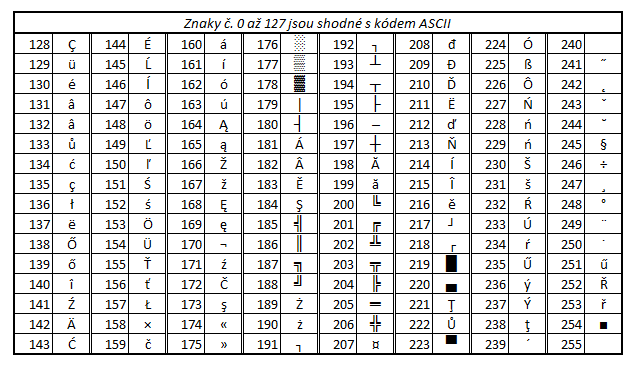
Note: Characters with grey background are not used. NBSP - non-breakable
space.
Kód Kamenických
Another character set which can be used under MS DOS for Czech and Slovak. This code was named according to the authors - Jiří and Marian Kamenics. This character set is derived from the set CP437 which was used for encoding characters of the English alphabet under MS DOS.
The first half of this set is identical with the ASCII code, Czech and Slovak characters can be found in the second half.
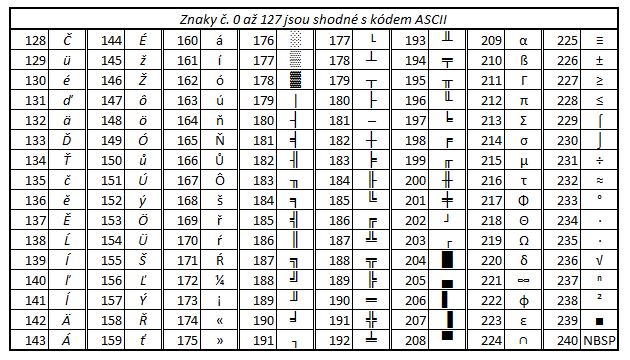
Note: Characters with grey background are not used. NBSP - non-breakable
space.
MacCE
The last mentioned character set for encoding Czech is the character set MacCE (or Mac Central European). This one is used for encoding Central European languages on computers made by APPLE under MacOS operating systems.
Unicode a Multibyte Sets
Except from the character sets mentioned above which are 8-bit (1 byte), you can use also multibyte sets. They usually define characters which are defined in the Unicode character set. This character set should contain all characters from all used national alphabets.
The development began in 1987 and in 1991 the Unicode Consorcium was founded (http://unicode.org/) which manages the set. The current version contains more than 100 000 characters but offers space for up to 1 114 112 characters with indexes (0)16 to (10FFFF)16. The complete table of all characters is available at the website of Unicode Consorcium (http://unicode.org/charts/).
The Unicode character set is implemented in operating systems using different codes (UTF-8, UTF-16, UTF-32) which use minimally 8 (UTF-8), 16 (UTF-16) or 32 (UTF-32) bits to store a single character - this is a minimal size, several characters can be stored using higher number or bits.
The advantage of this way of encoding is that characters from most languages are used so you do not have to choose the right encoding for your language. The disadvantage is a larger size of files and higher demands for file encoding.
Choosing Character Set
The simplest text editors (like Notepad under MS Windows) allow you to use only the most basic settings of encoding. More advanced editors (like PSPad) offer more options.
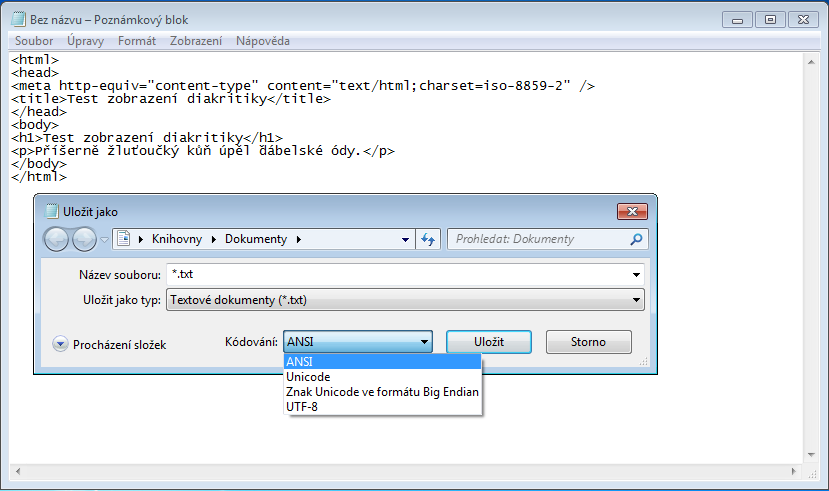
Notepad
Notepad offers only basic possibilities for changing the character set. You can choose from ANSI, several Unicode sets and UTF-8. In case of UTF-8, the selection of character set is clear. Using the ANSI character set is more difficult. In this case the character set depends on the language settings in the operating system. In case that Czech language is set, the character set Windows-1250 will be used.
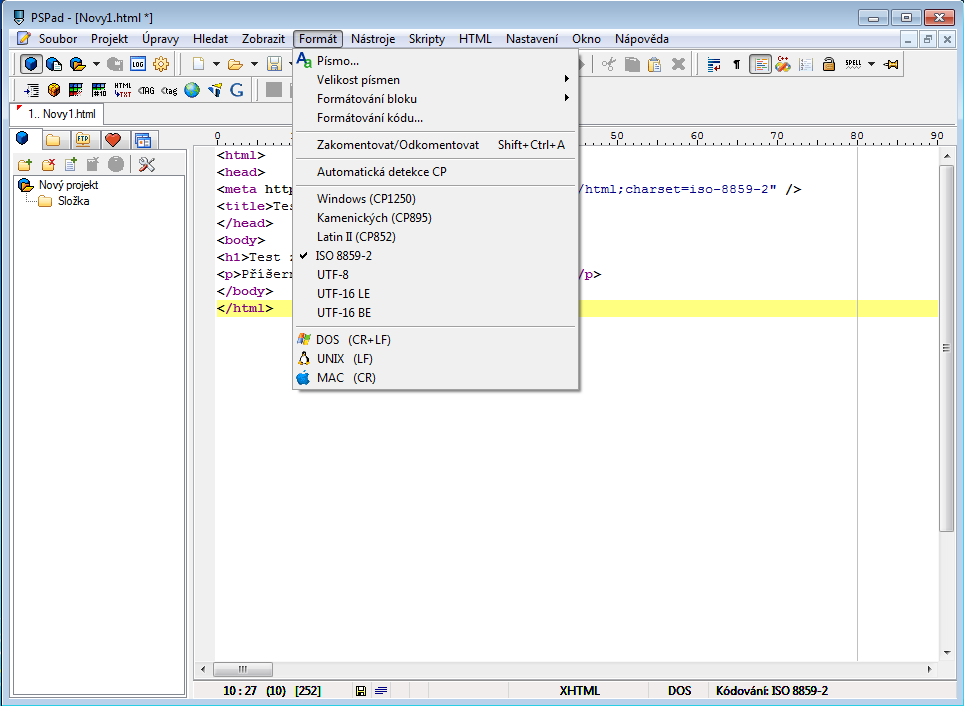
PSPad
Advanced editors offer you more advanced settings of character sets, you can use very popular PSPad for example (http://www.pspad.com/cz/). This text editor can be used (except from writing unformatted text) for editing parts of source codes in different programming languages or to create HTML pages.
A great advantage is that it can save documents in the character set ISO 8859-2 and in more other sets compared to the Notepad.
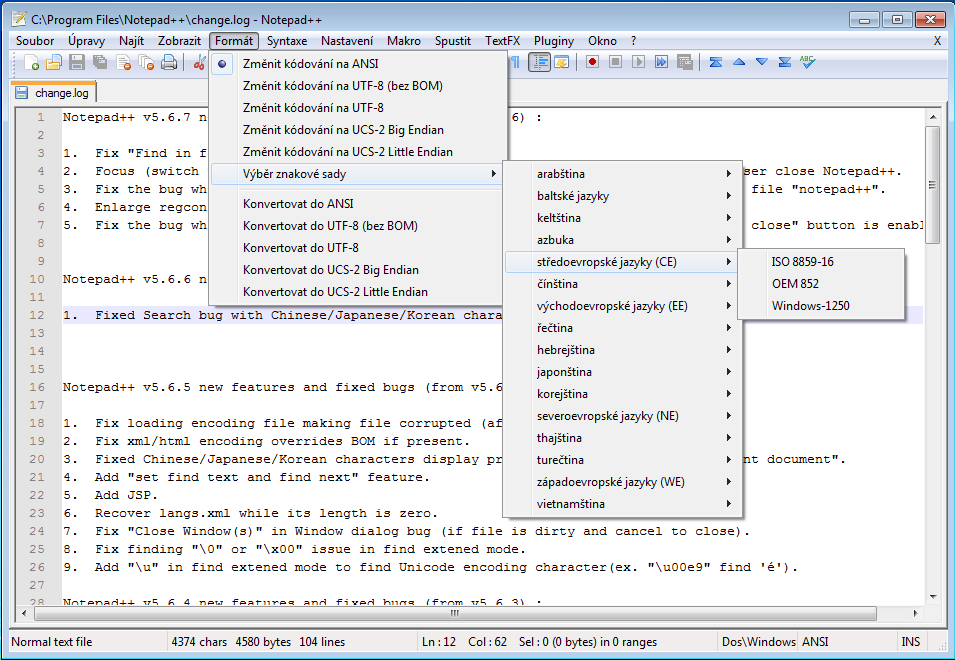
Additional Text Editors
Except the popular PSPad there are many other text editors which can set the character encoding. We can introduce for example Notepad2 (http://notepad-plus.sourceforge.net/uk/site.htm) or Notepad++ (http://notepad-plus.sourceforge.net/uk/site.htm) which can be seen in the following image.
Conversion of Character Sets
Software
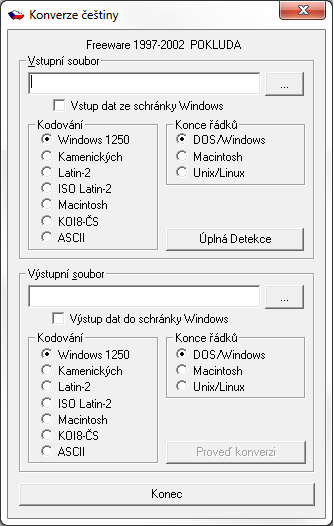
In case you need to convert your file to another encoding you can use one of many applications which are usually available for free in the Internet. A good example can be the application "Conversion of Czech" (http://www.pokluda.com/FreewareCz.aspx). This application is easy to control. You only choose the source and the final file (you can load data from the clipboard or save the final data to the clipboard), then you set the encoding of the source and the final file and click on the button "Proveď konverzi". This application supports the most of known Czech character sets (Windows-1250, Kód kamenických, CP852, ISO 8859-2 and more). There is one disadvantage because it does not support Unicode encoding which means character sets UTF-8 and UTF-16.
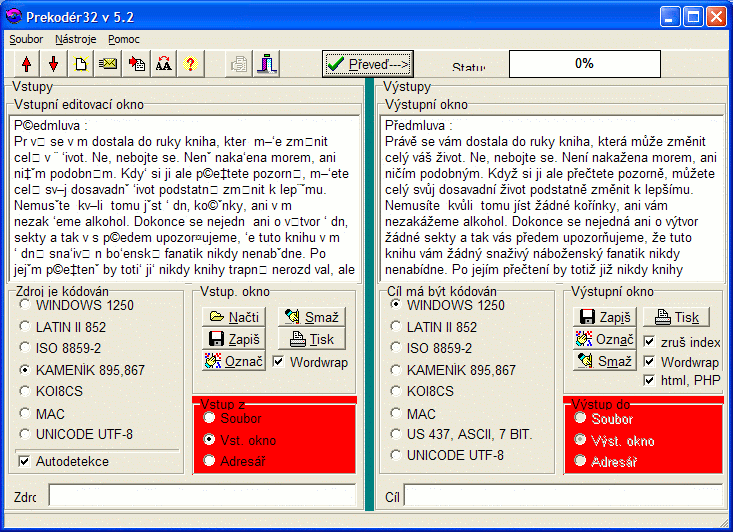
Another program is from the shareware category and its name is Prekodér (http://zmsoft.cz/prekoder/index.html). This program can be used for free for a month and it offers you also the possibility to convert text to UTF-8 compared with the previous one.
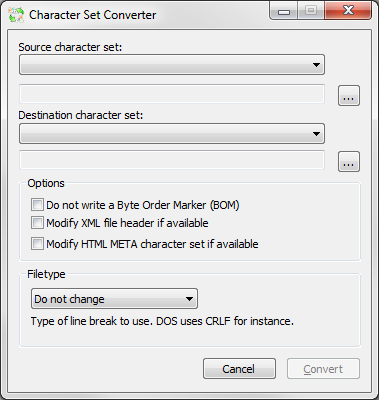
The previous programs were aimed to Czech character sets. Sometimes you might want to convert your document to a different character set. To make such a conversion you can use the application Character Set Converter (http://www.kalytta.com/tools.php) which offers you a large list of character sets, however, it is only a shareware.
Online Tools
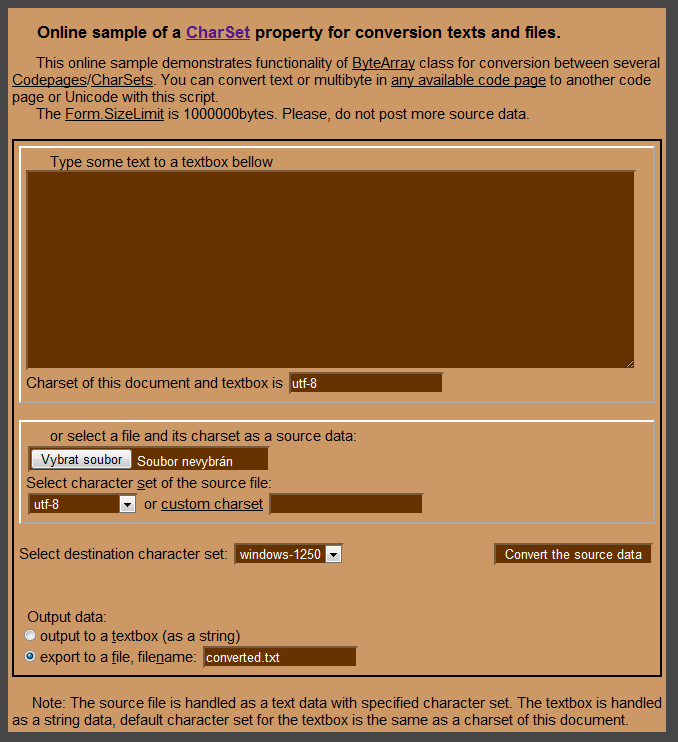
Besides these applications which can be used to convert diacritic and which were partly described in the previous chapter, you can also use online tools for converting a text to a different character set. A good example can be the following application at website motobit.com (http://www.motobit.com/util/charset-codepage-conversion.asp) which offers converting a text to different character sets and saving the file with it.
There are many other convertors, we can mention for example this website: http://kanjidict.stc.cx/recode.php which offers only basic possibilities of conversion compared to the previous one.
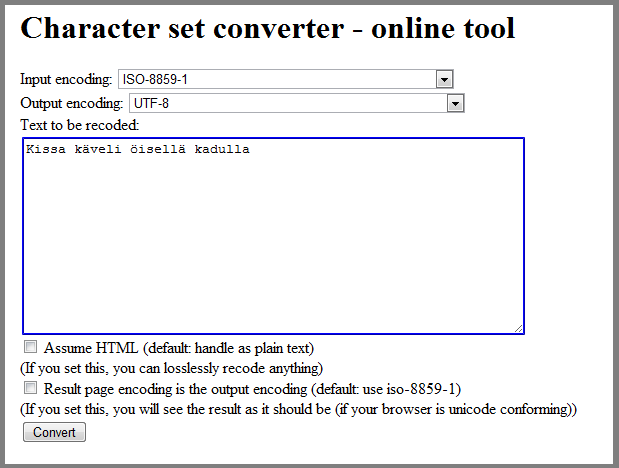
Using Character Sets on Web
The problematic of character sets is also necessary to be solved when creating WWW pages. The document which you create can be saved using one of the mentioned character sets.
Besides saving the document in a suitable character set, you have to tell the information about used character set to the browser. In case you do not tell it, one of the following two possibilities will be used:
- Default encoding or last used character set will be used.
- Browser will try to detect the character set automatically.
In the first case there is a risk that our document was created using a different character set. The second case can result in a wrong detection and the text can be unreadable as illustrated in the following image.
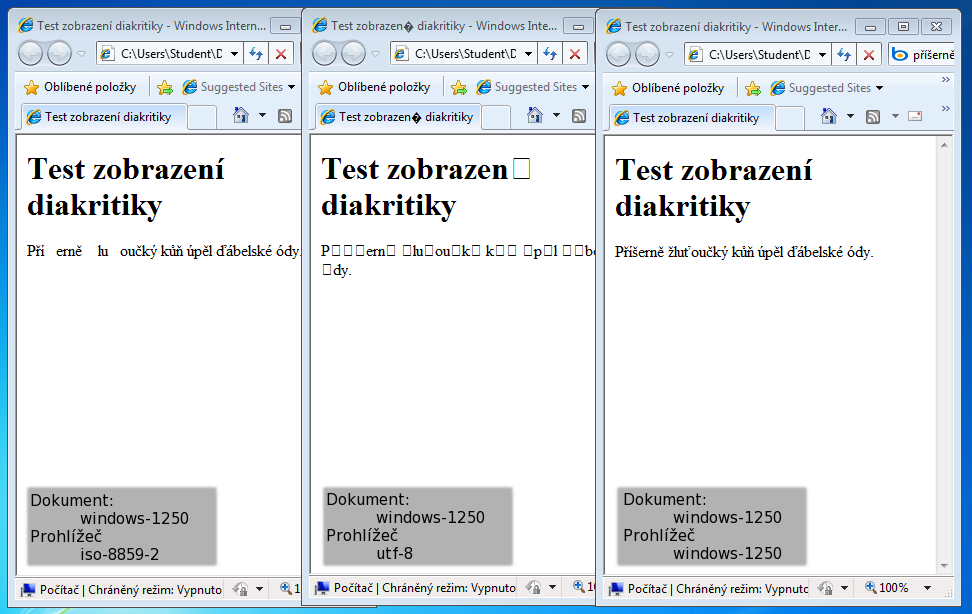
To ensure that a correct detection will be done you have to insert the following META tag:
<meta http-equiv="content-type" content="text/html;charset=znakova_sada" />Replace the text znakova_sada with your chosen character set. For encoding of Czech documents you can use for example one of the following names: iso-8859-2, windows-1250, UTF-8, …
Additional Texts
Questions
- What is text encoding?
- Which are the most used encodings for Czech language?
- How can you change a character set easily?
- Which tools for changing the text encoding do you know?
- Show how to change text encoding using an on-line application.
- Show how to change text encoding inside a web browser.