
Skenování a OCR
 Obsah lekce:
Obsah lekce:
- Skenování dokumentu
- Skenování do PDF
- Adobe Acrobat a OCR
- Extrakce textu
- Samostatný úkol
Obsluha skeneru
Obsluhu skeneru si budeme ilustrovat na jednom konkrétním typu, ale obsluha jiných skenerů je obdobná. Skener je připojen k počítači zpravidla prostřednictvím USB kabelu.
Odklopte víko skeneru a umístěte na něj dokument, který si přejete skenovat (viz obrázek). Skenovat se bude pouze plocha, která leží na skle skeneru (analogie kopírky). Principem skeneru je, že se pokusí „vyfotit“ to, co má na sobě položeno a uložit to (zpravidla jako obrázek) do počítače (na jeho pevný disk).

Celý proces skenování probíhá tak, že po spuštění tohoto procesu projede určitou rychlostí (závisí na zvolené kvalitě skenování) snímací hlava skeneru pod sklem a vytvoří soubor obsahující to, co po cestě viděla – tedy kopii předlohy. Je dobré, abychom skenovaný dokument (předlohu) umístili do skeneru co nejrovněji, dle potřeby, ale není problémem výsledný obraz dále zpracovat či narovnat (vyžaduje to ale alespoň základní znalost nějakého programu pro práci s obrázky).

Nejjednodušší situace je, když se skenuje přímo list formátu A4. Stačí jej do skeneru položit a skener zavřít (horní víko). U čehokoliv jiného (knihy apod.) není nutno víko zavírat (knihu můžete držet přitisklou co nejvíce ke skeneru a víko nezavírat). Výsledný skenovaný obraz bude tím lepší, čím blíže bude předloha sklu skeneru.
Přepis dokumentu na papíře do textového procesoru (např. Wordu)
Pokud chceme přepsat text například z knihy do programu pro práci s textem (například Indesign nebo Word), pak je možné tento proces nechat automatizovaně provést počítačem. Je nutno provést skenování textu (získáme obrázek obsahující text) a následný převod znaků na obrázku do písmen. Počítač umí (do určité míry) pomocí programu na rozpoznávání textu (tzv. OCR z anglického Optical Character Recognition – rozpoznávání znaků) v obrázku najít písmena a rozpoznané znaky vložit do libovolného programu pro práci s textem.
Následující postup popisuje skenování dokumentů a metodu OCR, naskenované dokumenty lze pro další kroky stáhnout zde: kniha-sken-1.pdf, kniha-sken-2.pdf
Postup
- Vložíme do skeneru požadovaný dokument.
- Na skeneru stiskneme tlačítko PDF (analogicky můžeme použít software pro skener)

- Nyní by mělo dojít k tomu, že se rozsvítí lampa ve skeneru, spustí se software skeneru v počítači a začne probíhat proces zahřívání lampy. Ten nějakou dobu trvá (+- minuta, na obrazovce je malé okno s nápisem Scanning… a textem „Adjusting the lamp. Please keep the document cover closed.“). Je tedy potřeba počkat než se dokončí (pokud máte ve skeneru předlohu, u které je to možné, tak sklopte víko skeneru zpět na předlohu – položte jej).
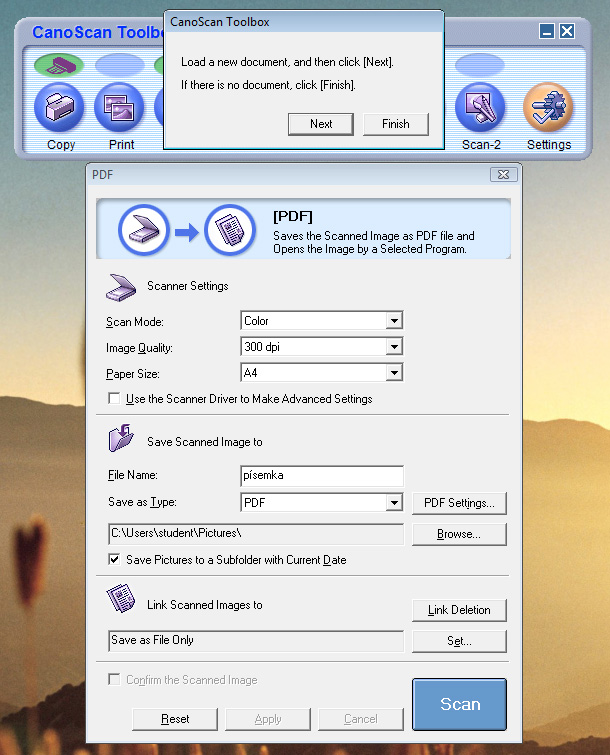
- Po naskenování dokumentu vznikne soubor ve formátu PDF, který se uloží pod definovaným jménem (položka File Name) na pevný disk počítače (z obrázku výše vidíme, že do složky C:\Users\student\Pictures). Po naskenování se nám ale objeví okno průzkumníka s naskenovaným souborem, takže jej nemusíme sami vyhledávat (viz následující obrázek).

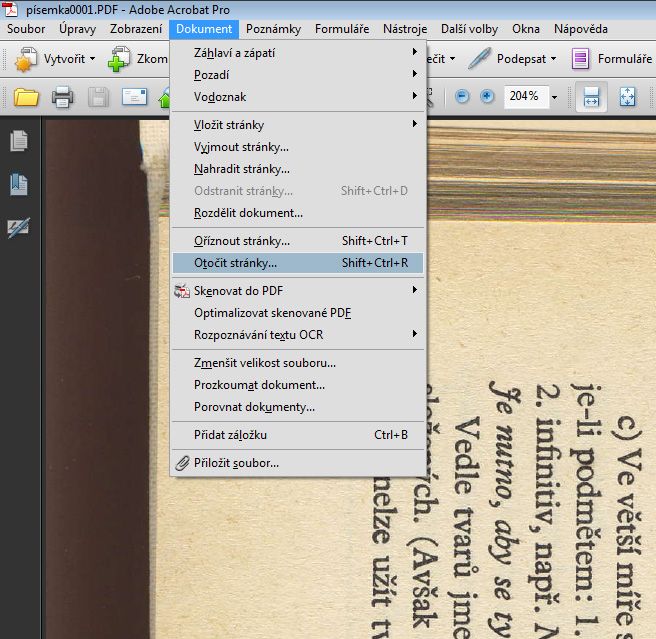
- Poklikáním na soubor jej otevřeme v programu Adobe Acrobat (pozor, nejedná se o běžný Adobe Reader), který nám umožní převést obrázek v PDF souboru na text. V případě, že máte předlohu naskenovánu převráceně, pak je dobré naskenovaný dokument otočit v požadovaném směru v programu Adobe Acrobat (menu Dokument > Otočit stránky).
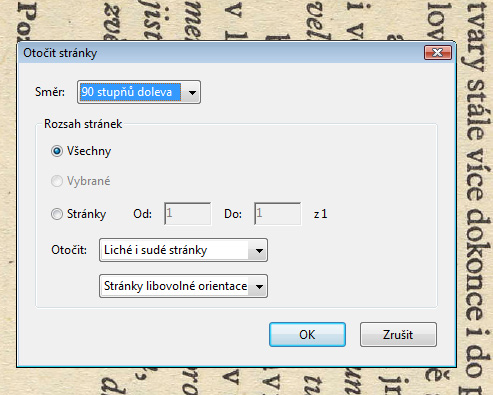
Ve zobrazeném okně Otočit stránky zvolíte směr otočení podle potřeby a asi vyberete v rubrice rozsah stránek položku všechny. Stiskněte tlačítko OK.
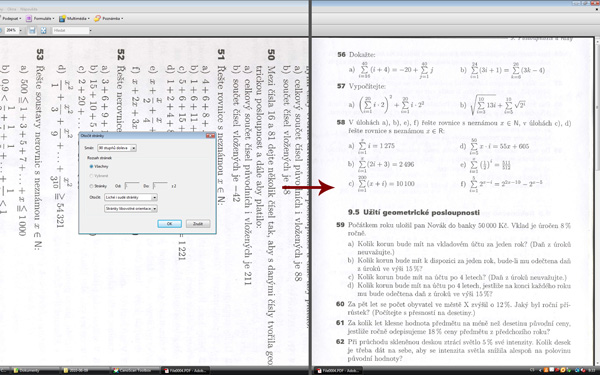
- Nyní bychom měli mít naskenovaný soubor otevřený a správně natočen (viz obrázek).
- Nyní je – v případě potřeby – dobré „ořezat“ v obrázku požadovaný text (často se stane, že jsou na obrázku například kusy sousedních stran, okraje knihy apod.). Jde nám o to, že chceme na každé straně mít jen obdélníkovou část obsahující požadovaný text. K tomuto účelu slouží nástroj oříznutí (viz ikona na následujícím obrázku).
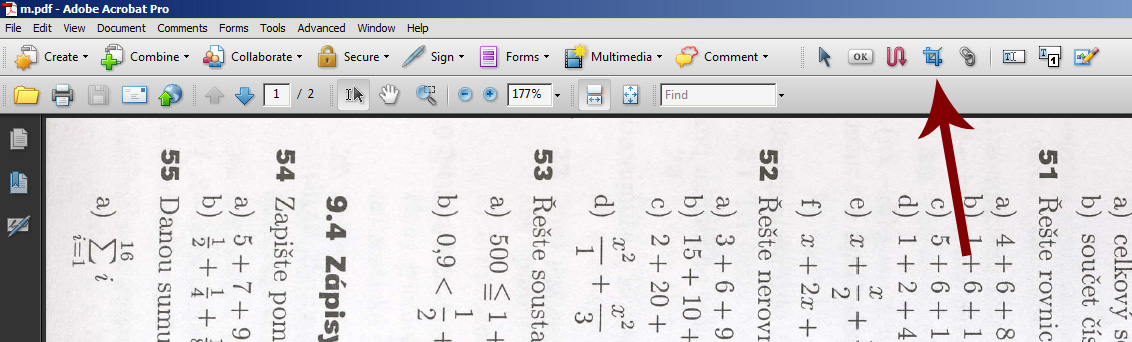
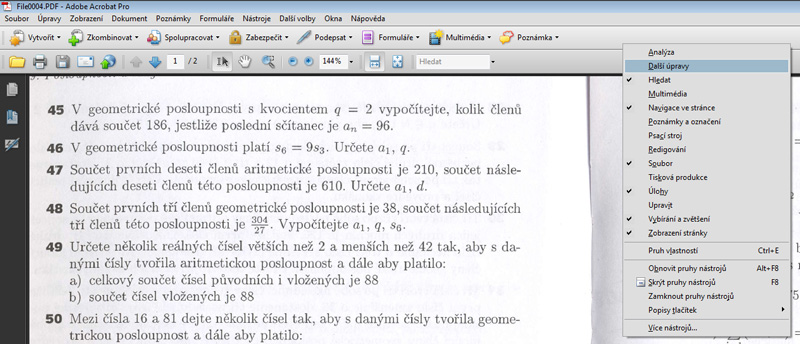
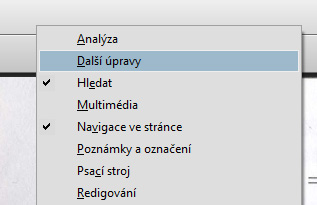
Pokud tuto ikonu v nabídce nevidíme (není přítomen panel, ve kterém je obsažena), pak na horní lištu s panely klikneme pravým tlačítkem myši a z nabídky vybereme položku Další úpravy.
- Po této akci by se měl objevit panel s nástroji pro úpravy obsahující ikonku nástroje oříznutí. Zpravidla se tento panel objeví jako tzv. plovoucí (lze s ním pohybovat po obrazovce myší tažením za horní část panelu).
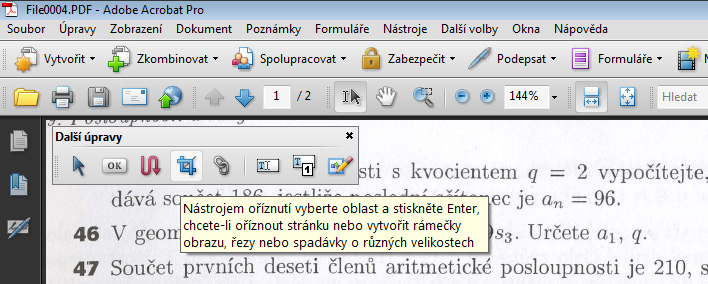
- Panel můžeme nechat plovoucí (přetáhnout si jej dle potřeby) nebo si jej umístit k ostatním nástrojům do nástrojové lišty.
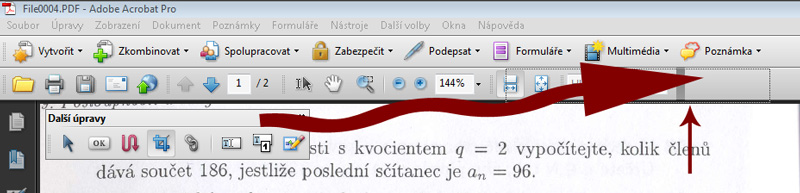
- Ve výsledku nám nástroje pro úpravy již pěkně „sedí“ v nástrojové liště a lze je pohodlně vybírat a používat.

- Nyní kliknutím na ikonku nástroje oříznutí nástroj vybereme a vytvoříme myší v dokumentu obdélník obdélník, jehož obsahem je požadovaná část dokumentu s textem, který si přejeme přepsat. Klikneme na libovolné místo v dokumentu (první roh obdélníku) a se stále stisknutým levým tlačítkem myši vyznačíme v dokumentu obdélník. Po vytvoření obdélníku pustíme levé tlačítko myši a v případě potřeby jej po vytvoření můžeme libovolně rozměrově upravit tažením za jeho strany.
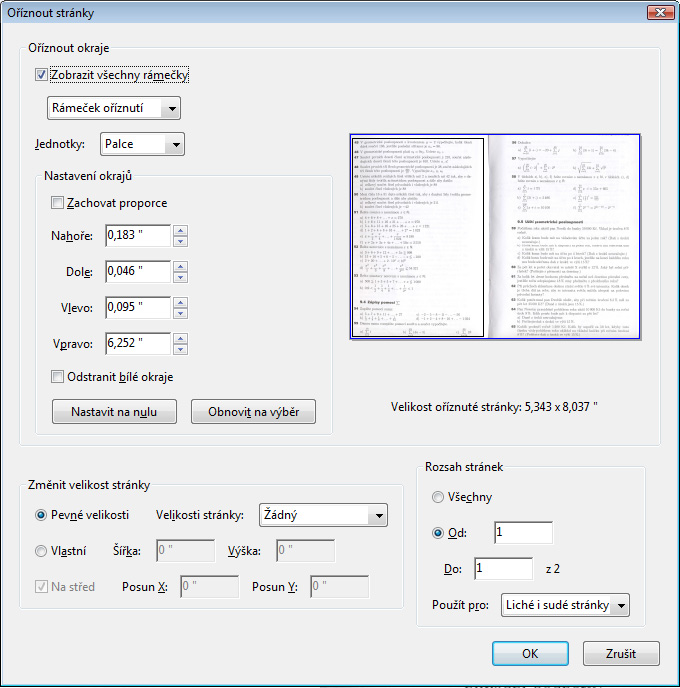
- Jakmile máme ořezový obdélník vytvořen, tak stiskneme klávesu Enter (všimněte si na jednom z obrázků výše, že pokud najedeme kurzorem myši nad ikonku nástroje, tak se po chvilce zobrazí malý žlutý obdélník s krátkou nápovědou o daném nástroji). Pokud tedy nevíte, co která ikonka znamená, tak se to takto stručně lze dovědět. Po stisku klávesy Enter by se mělo objevit okno jako na následujícím obrázku. Zásadní je zde v podstatě pouze opět volba Rozsah stránek, kde si můžete stejným způsobem ořezat všechny stránky dokumentu nebo každou jinak dle potřeby. Celý proces oříznutí dokončíte stiskem tlačítka OK.
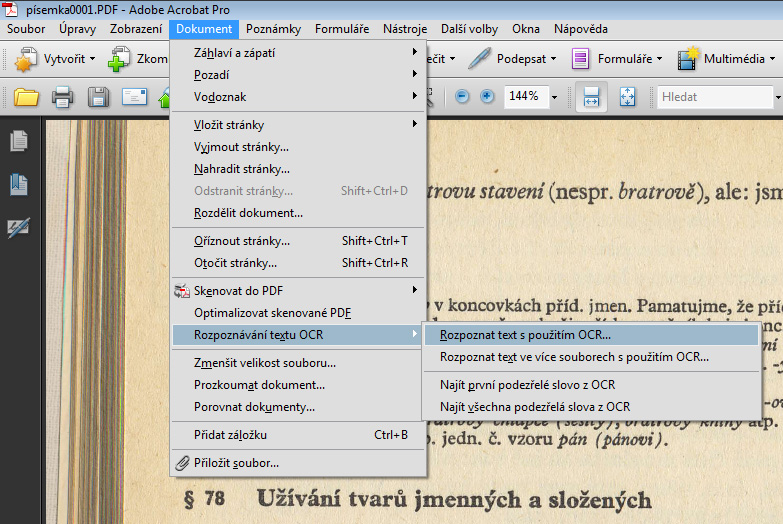
- Nyní již máme dokument připraven pro samotný proces rozpoznávání textu. V nabídce Dokument vybereme položku Rozpoznání textu OCR > Rozpoznat text s použitím OCR…
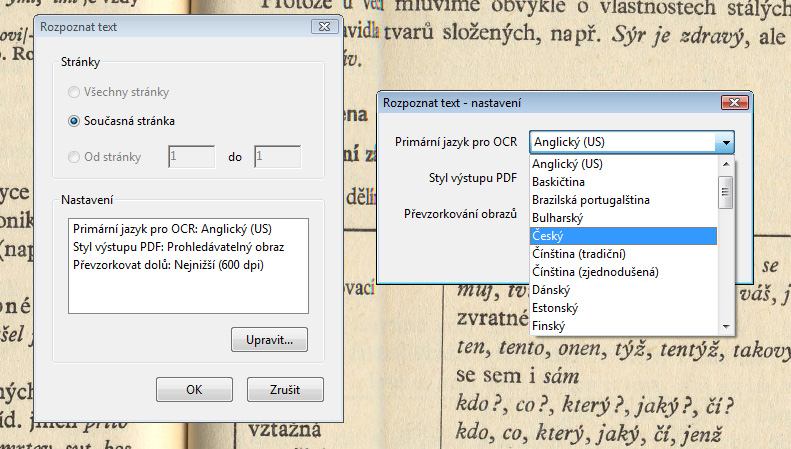
- Zobrazí se okno s volbami pro rozpoznávání. V něm je důležité zvolit požadované stránky, ve kterých chceme text rozpoznat a zkontrolovat nastavení. V nastavení je podstatná především položka udávající primární jazyk (jazyk zvolíme tlačítkem Upravit…). Samotný proces převodu spustíme v okně „rozpoznat text“ kliknutím na tlačítko OK.
- Adobe Acrobat se pokusí v obrázku rozpoznat písmena (OCR). Tento proces nějakou dobu trvá (záleží na velikosti obrázku, množství textu a výkonu počítače). Následně lze v pdf souboru pomocí nástroje pro výběr textu vybrat text a například nakopírovat do schránky. Zde je potřeba poznamenat, že programu se nemusí podařit rozpoznat všechna písmena správně (obtíže může působit například tisková kvalita, zvolený font, jeho různé řezy, nečistoty na papíře, podobnost písmen apod.).
- Ze schránky lze pak text vložit kam potřebujeme (např. do textového procesoru). Tam můžeme text opravit, měnit, doplnit apod.
Samostatný úkol
Použijte tento naskenovaný dokument, který představuje propozice pro turnaj. Použijte funkci OCR pro načtení textu a vyrobte obdobný dokument v Adobe InDesignu.
Loga můžete použít z následujících souborů: logo-zlin, logo-olomouc.
Nezapomeňte opravit všechny typografické chyby ve výsledném dokumentu a dbejte na to, aby byl výsledek co nejvíce podobný. Stejně tak důkladně zkontrolujte, zdali text přečtený metodou OCR neobsahuje žádné chyby - metoda není vždy plně spolehlivá (dokument bude obsahovat jednu chybu po použití funkce OCR).
Výsledný soubor z Adobe InDesignu exportujte do PDF, náhled je k vidění v následujícím obrázku.
